Data is a raw material or unstructured information, which we use to process the data to get the meaning full information.
class Student{
int sid;
String sname;
String scity;
Student(int sid, String sname, String scity){
this.sid = sid;
this.sname = sname;
this.scity = scity;
}
void display(){
System.out.println("-----Student Details-----");
System.out.println("student-id :- "+sid);
System.out.println("student-name :- "+sname);
System.out.println("student-city :- "+scity);
}
}
class JTC{
public static void main(String arg[]){
// raw data
int id = 101;
String name = "Vivek";
String city = "Noida";
// Processing the data
Student s1 = new Student (id, name, city);
// Getting the meaningful information of a Student
s1.display();
}
}
-----Student Details-----
student-id :- 101
student-name :- Vivek
student-city :- Noida
In the above example, we are trying to understand what raw data is and how we can process it to obtain meaningful information. As we can see in this example, we have two classes: `Student` and `JTC`. In the `JTC` class, we have a main method that contains three local variables: `id = 101`, `name = "Vivek"`, and `city = "Noida"`. Initially, when we look at these data points, we may not understand the meaning of `id`, `name`, and `city`. This means that, at this stage, these are raw data, or in other words, they do not make any sense. However, when we use the same data to create an object of the `Student` class, we are processing the raw data. After this processing, we can easily understand that `101`, `Vivek`, and `Noida` represent the student ID, student name, and student city, respectively. This means that from the same data, which was raw before processing, we are now obtaining meaningful information.
• Data Structure is a concept or fundamental principle for storing data in an organized manner.
• The advantage of using a data structure to organize data is that we can perform various operations on large amounts of data in a very short time.
• The basic operations performed on data are:
Insert: - Adding new data to the storage.
Delete: - Removing existing data from the storage.
Update: - Modifying existing data in the storage.
Select: - Retrieving data from the storage.
Search: - Finding specific data within the storage.
Sort: - Arranging data in the storage in a specified order, such as ascending or descending.
There are 2 different types of Data Structure.
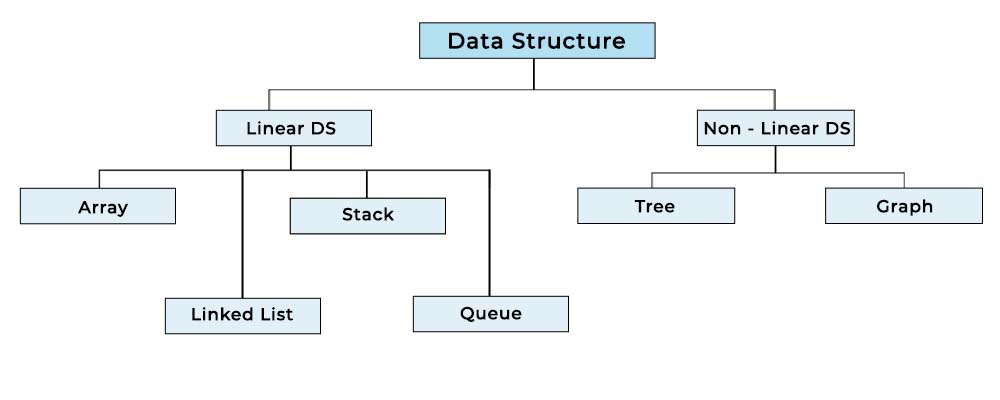
In a Linear Data Structure, data is stored sequentially, meaning each piece of data is stored one after another.
Arrays, Linked Lists, Stacks, and Queues are the most commonly used linear data structures, and we will discuss these in further detail in upcoming articles.
Unlike Linear Data Structures, in Non-Linear Data Structures, data is not stored sequentially. Instead, data is organized in a hierarchical format.
The most commonly used Non-Linear Data Structures are Tree and Graph-based structures , which we will discuss in detail in upcoming articles.
Q. How can we choose a Data Structure based on business logic?
This is one of the most important questions that every student, reader, or developer must understand before starting their journey with Data Structures.
As we know, there are various Data Structure options available, and the good news is that we can perform most basic operations in almost all Data Structures. For example, we can perform the select operation in both Arrays and Linked Lists.
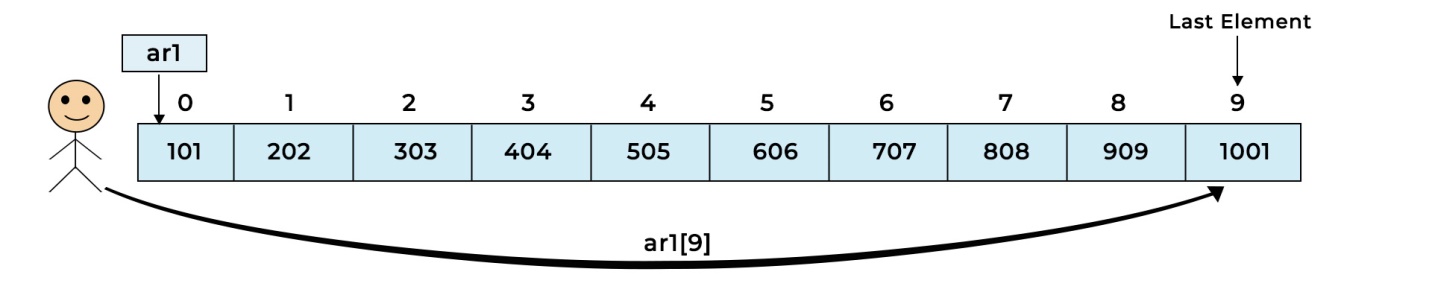
In an Array, the time complexity of the select operation is O(1) (constant time). This is because Arrays store data using index representation, allowing for random access. For instance, if we have an array of length 10 and need to retrieve the data from the last position, there's no need to access the first 9 elements sequentially. Instead, we can directly move to the last position and retrieve the data.
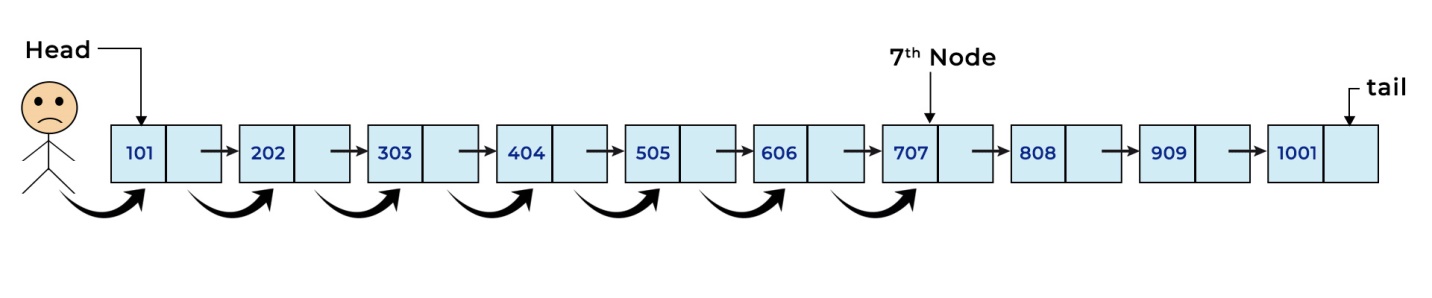
Unlike the Array data structure, a Linked List stores data using Nodes. A Node is a memory allocation that contains data as well as the address or reference of the next node. Therefore, when we need to retrieve data stored in a Linked List, we must follow sequential access.
For example, if we have a Linked List with 10 nodes and want to access the 7th node, we must first traverse the first 6 nodes before reaching and accessing the 7th node. This means the time complexity of the select operation in a Linked List is O(n).
In conclusion, for the select operation, using an Array is more efficient than using a Linked List.
Conversely, for insert or delete operations, a Linked List is often a better choice than an Array.